
Last February I was lucky enough to be able to give a presentation on the grand ballroom stage at one of the bigger developer conferences in the bay area: DeveloperWeek.
I gave a presentation on developing reusable microservices through 10 principles. Principles which we have explored over the years on the mu.semtech blog. What is a reusable microservice? Without giving a precise definition here are some properties to which such a microservice should adhere:
- a microservice should be swappable for another microservice that offers the same endpoints (the typical example is an update of the same microservice)
- a microservice can be considered stateless
- a microservice communicates over HTTP
This article gives an overview and a small description of the principles and why it helps to develop microservices that are resuable.
1 Single source of truth
From the microservice’s perspective there is only one single endpoint which holds the complete truth about the world. This source can be distributed using this functionality on a database or software functionality layer such as the SANSA stack. But it can also be composed, think for instance of Ontario.
2 Set of actions on data
Each microservice contains only a little consistent piece of functionality on data. Now that is super vague, right? What is consistent? Well, I don’t mean consistent to the other actions offered by this microservice, but rather consistent to its data model.
Take for instance login and registration services. Both of them are user related so you might think it is a good idea to offer both functionalities in the same microservice. However this is far from optimal since both functionalities require vastly different data models. The login service will need a data model that manages username, password, date of birth, real name, … while the registration service will be interested in the session, username and password. Even though at a first glance this is a single set of functionalities, namely user management, it is not the case from a data perspective.
3 No horizontal communication
Within the application block no microservice talks directly to another. Take the setup shown below for example. You will see that #white# talks to #dark-blue# but they only talk to each other and in this configuration. But from the perspective of the dispatcher and from that of the database they are a single microservice. This is one of the most important principles. Without this we would start introducing hidden dependencies all over the application.
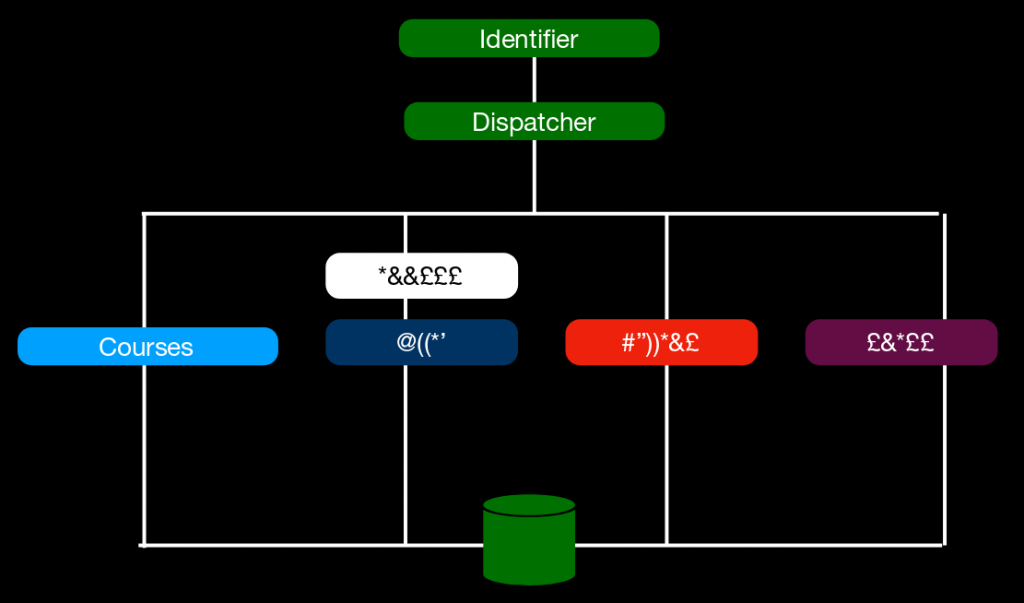
Take for instance if #pink# would call an endpoint on #dark-blue# every time a certain hook gets executed. Or to make it more concrete, #pink# creates an invoice and #dark-blue# sends that invoice to the customer. That is innocent enough but if we remove the #dark-blue# microservice some other service will need to pick the ‘send-invoice’ action up. By allowing these horizontal hooks we create a hidden dependency, a contract between the microservice and the maintainer of the application. If you install me in your application then I expect you to install something to handle actions X, Y and Z.
The second unwanted side effect of this is that #pink#, even though it only creates the invoice, can only be used if you want to create and mail an invoice. But we still want to handle business logic, if not through hooks and messages then how do we go about implementing that?
4 Business logic through UX
We came up with two solutions to the business logic problem. The first one is to solve it through the UX. Note that this should only be done in cases where it makes sense. We don’t want to just shift the complexity of the backend to the frontend, where it is almost always worse! To illustrate when this is OK we use the example of search. If I have a search microservice and a resource microservice then I feed the search microservice a string and it will give me back an ID. I then use this ID to obtain an object from the resource microservice. This a clean decoupling of both functionalities. The search needs not to know how an object is composed and the resource has no idea about the indexing scheme used. Both can operate, be changed and installed independently.
5 Business logic through reactive programming
To go back to the create invoice and mail example, that is clearly a case of complexity that should not be handled in the frontend. To handle this we have come up with what we call ‘reactive programming’. I know it is an overloaded term but we don’t intend that to be what you get if you google the term. Rather it is a framework functionality that allows a microservice to be notified of the pure data changes (think triples here) that are about to be introduced to the database. For more information have a look at the reactive programming blog posts.
6 Configuration
Code that gets used for more than one use case and from more than one angle tends to be robuster and more bug free than code that doesn’t get the same usage. Furthermore, because it has already been used in a variety of ways chances are that the way you want to put it to use may already be largely supported. Within mu.semte.ch the champion when it comes to reuse is mu-cl-resources. Which is our default resource offering microservice. It supports a full fledge JSONAPI compliant service on top of a SPARQL backend.
7 Controlled vocabularies
Controlled vocabularies serve not only to facilitate standardization – which they do very well – but because concepts in vocabularies are represented using URIs they have the ability to be materialized so that they also contain, within themselves, unambiguous documentation as to their intent.
My favorite example of the incredible power of these controlled vocabularies is the work that Aad and I did recently on an Ember component that supports Oauth2. We have designed a backend microservice that handles the storing of the Oauth2 credentials in the database. And it all just magically worked together with a component that Erika had written well over 3 years ago! Out of the box, without us going about checking her implementation.
8 Push updates
We want to provide a standardized way to provide the user with push updates. These push updates will allow us to create applications that are from the user’s perspective incredibly responsive. Our standardization builds on either long pulling or web sockets and Ember Data as a frontend datastore.
9 Reasoning
With the advent of powerful database technologies such as the SANSA stack comes the ability to apply reasoning to large datasets and to do it in a time that allows application to behave normally. This reasoning can be used for classic purposes such as implicit knowledge definitions and data quality control but it can also help us reuse more services.
10 Access control
The last part to touch upon is a database that has access control built-in. In this way it allows us to separate this important part of application design from both the business logic and from the data it operates on. The separation from business logic means that we can now build microservices without any access control in mind and still deploy them with access control present. Doing so we achieve, yes, even more reusability. Separation from data empowers us to change the access control rules easier and it allows us more freedom when it comes to defining those rules.
The complete presentation as given at DeveloperWeek can be found here.