
The problem with most triple stores is … they tend to be slow. At least slow compared to their schema-full counterparts. It seems the cost of not defining a fixed schematic structure upfront is a not easy to avoid. We have been thinking about various models and solutions to mitigate this issue for specific applications. With the simplicity of the mu.semte.ch stack it is easy to add caches left and right but in the end that does not solve all problems. This post is intended to present an idea on how to add a solution by making the triple store distributed.
What kind of distributed?
There are various models of distributed stores and maybe we explore other in subsequent posts. In this post we present one way of distributing a triplestore across multiple instances.
The high-level idea is that a delta-service detects changes which would be introduced by update-queries. These updates are dispatched to a set of replicated triplestores. Queries and updates are ordered correctly to ensure updates are visible when a combination of read and write queries are executed.
Terminology
A quick overview of the terminology used below as it is quite ambiguous.
- query: a SPARQL query that is not an insert or delete query.
- update: a SPARQL query that is an insert, delete or delete-insert-where query.
- SPARQL query: a query or an update.
Architecture
A DSE (Distributed Sparql Endpoint) consists of a distributed SPARQL Endpoint Controller, a delta calculating microservice, a slave controller microservice, optionally a base slave store and then one or more slaves stores.
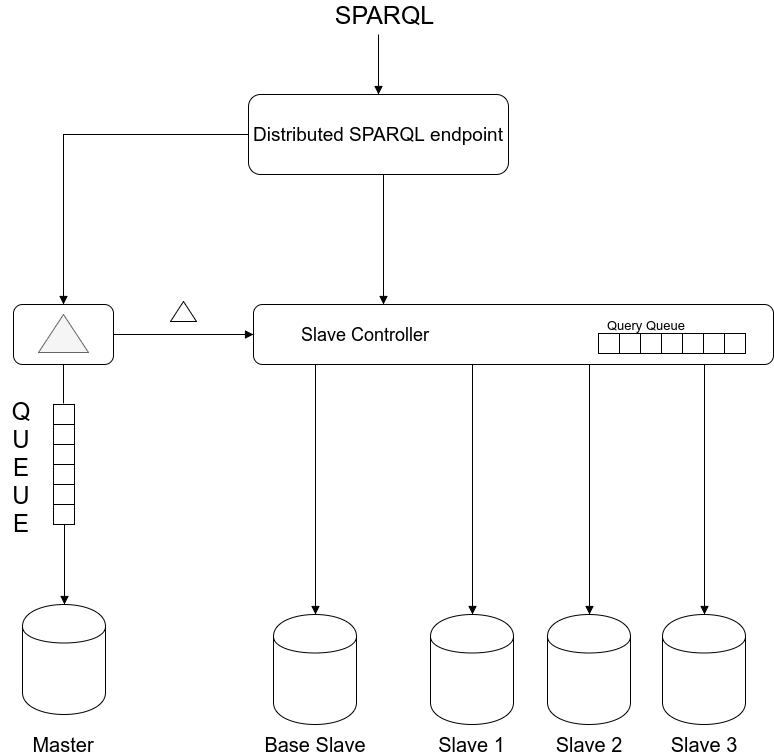
Distributed SPARQL Endpoint Controller (DSEC)
The DSEC acts as the entrypoint for the DSE. The most basic form of its functionality would be to split the incoming SPARQL queries into queries and updates. Although updates change the database’s state, the DSEC is itself is almost fully stateless. A notable exception is an increasing number attached to each incoming SPARQL query. This number allows us to prevent the execution of queries before all updates that were sent earlier have been applied.
Delta Calculating Microservice
The delta microservice calculates which triples are changed based on a received query. It has three distinct responsibilities:
- Maintain a queue of pending updates;
- Calculate the delta that would be introduced by executing the [lowest] update on the queue;
- Execute those delta’s on it’s own [master] data store.
Note: The Delta Calculating Microservice could maintain it’s state in a private SPARQL store to facilitate rebooting the component without loss of state should it go down. Rolling back should not happen as any update would be translated into an update of the form WITH <graph> INSERT DATA { … triple … }. In this case we can assume the underlying triple store to handle the cases where roll back is needed.
Slave Master Microservice
The Slave Master Microservice maintains the slaves stores’ lifecycle including creation and termination. This microservice also manages a queue of queries and uses a load balancing algorithm to assign the query to a slave. When the Delta Calculating Microservice sends out a delta report the Slave Master Microservice will inform all slaves of the change in state (in essence nothing more than running the above mentioned ‘simple’ update). The Slave Master knows the latest update number for each slave and can take this into account before sending queries.
Conclusion
The ideas in this post build heavily on the reactive programming ideas presented in earlier posts. The main weakness of this approach is still the single point of failure that is the delta calculating component itself. This component could be made distributed by further enhancements. It is currently the only component that processes update queries in this ecosystem. Maybe for a system with low write and high read access this would be a valuable asset. Keep tuned for the PoC!